Or try one of the following: 詹姆斯.com, adult swim, Afterdawn, Ajaxian, Andy Budd, Ask a Ninja, AtomEnabled.org, BBC News, BBC Arabic, BBC China, BBC Russia, Brent Simmons, Channel Frederator, CNN, Digg, Diggnation, Flickr, Google News, Google Video, Harvard Law, Hebrew Language, InfoWorld, iTunes, Japanese Language, Korean Language, mir.aculo.us, Movie Trailers, Newspond, Nick Bradbury, OK/Cancel, OS News, Phil Ringnalda, Photoshop Videocast, reddit, Romanian Language, Russian Language, Ryan Parman, Traditional Chinese Language, Technorati, Tim Bray, TUAW, TVgasm, UNEASYsilence, Web 2.0 Show, Windows Vista Blog, XKCD, Yahoo! News, You Tube, Zeldman
ongoing by Tim Bray
ongoing fragmented essay by Tim BrayLife During Class Wartime 3 May 2026, 7:00 pm
War is bad. Don’t start one. But we’re already in a class war and we’re losing. Where by “we” I mean most people; the winning side comprises, roughly, the richest 0.1% of the population, who are morphing into a hereditary aristocracy. [I mean that, see below.] So, what to do in a war one didn’t choose?
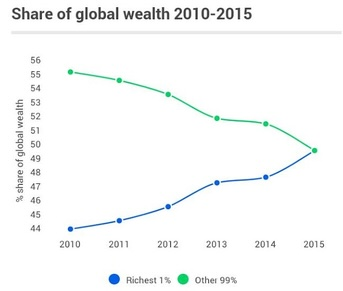
How bad is it?
It’s really bad, and getting worse fast. I recommend cruising through Wikipedia’s excellent article on Distribution of wealth; maybe jump straight to the Wealth inequality section. I’ve pulled one helpful graph, sourced from Oxfam, into the margin. The article has loads of other statements of the form “The richest X compared to the poorest Y have Z times️ as much.” The values of X, Y, and Z are uniformly saddening.
As a resident of a wealthy West-Coast New-World city, the effects of pathological inequality are in my face every day: Bentleys gleaming on the road, ragged people huddled in the rain cadging cash outside the drugstores, thousands homeless.
Why is that bad?
It’s not only sinful by any sane definition of sin, but stupid, inefficient, and damaging. I turn once again to Wikipedia: Effects of economic equality. I’ll add one pointer to an effect that is less obvious: It exacerbates the unaffordability crisis.
One effect of the increasing imbalance between the ultra-wealthy and everyone else is the emergence of, effectively, a hereditary aristocracy. “Wait!” you exclaim, “How about high income-tax rates for the wealthy, and inheritance taxes?” You might well ask. It turns out those are no longer operative. I’ll get into details about that, but first…
A parable: Grant Gustavson
I am, as previously related (see Southsiders and Fútbol Joy) a fan of the Vancouver Whitecaps Football Club (VWFC) who play in Major League Soccer. It’s affordable, light-hearted, high-drama, high-quality entertainment and has lifted my spirits notably in the recent dark years.


Vancouver Whitecaps fans bring the love
However, it appears that Vancouver’s about to lose the Whitecaps, at the whim of a Vegas-based purchaser, of whom The Athletic writes:
The potential buyer is Grant Gustavson, the son of Kentucky billionaire Tamara Gustavson and grandson of B. Wayne Hughes, founder of Public Storage, according to multiple sources with knowledge of the discussions. Forbes estimates Tamara Gustavson’s net worth at $8.5 billion.
Gustavson, 30, lives in Las Vegas. A graduate of the University of Southern California, he has been involved with the athletic department at his alma mater and helped to develop the Name, Image and Likeness (NIL) program there. He continues to work with the USC basketball program and is also involved in the management of his family’s farm, “the country’s premier thoroughbred farm with decades of storied champions throughout the stables.”
So this fucking youngster, who has life experience working at the gym at USC (where his Mom’s on the Board of Trustees) and helping out at the family farm, can reach out his mighty hand and snatch away a popular pleasure from another nation. Droit du seigneur in action.
Staying rich
I highly, highly recommend Our Tax System Should Make You Furious from the NYT. By “our” they mean America’s. First, it addresses the canard that the tax system is actually progressive; people who like things the way they are like to say “Forty percent of people pay no federal income taxes, and then the top 1 percent pay 40 percent of the income taxes.” (Tl;dr: Somewhere between highly misleading and a big fat lie.)
Second, it explains the mechanisms by which generational wealth is accumulated and preserved, effectively in perpetuity. People like Bezos and Musk pay basically no income tax, and the way they do it isn’t complicated or hard to understand.
There is actually a family of financial products called Dynasty Trusts. The first ad that popped up in response to my Web search had the marketing copy “Dynasty trusts: preserving family assets for future generations”. Or, put another way, “Dynasty trusts: Starving beggars in your neighborhood.”
Revenue from the rich
So what can we do about it? Tax expert Ray Madoff, the interviewee in the “Should Make You Furious” piece, has smart things to say. Then there’s Thomas Piketty: “Opponents of the tax on the ultra-wealthy lack historical perspective”.
The common thread is taxation of wealth not income, because the arcane abstractions of accounting make income too easy to hide. The argument is that a wealth tax of say 2%/year, starting at a threshold of a few tens of millions, won’t impair the lifestyles of the seriously wealthy, but still yield systemically important public-sector revenue
Also worth reading, from the International Monetary Fund: Game-Changers and Whistle-Blowers: Taxing Wealth. Among other things, it reports that the proportion of wealth that is hidden in one offshore tax shelter or another is pretty small, ranging from 8% in the developed countries up to 30% in poor nations. Apparently it’s harder to hide wealth than income.
Good karma
If wealth taxation won’t touch wealthy lifestyles and will help build a safer, calmer, happier society, it feels sort of irrational to oppose it. And some of the wealthy don’t. My favorite example of this is Avi Bryant. Check out I’m a Millionaire. Tax Me More, Please and Meet a millionaire who wants Canada to tax the rich. [Disclosure: I made a nice little chunk of money when my tiny investment in Avi’s startup turned into pre-IPO Twitter shares.] I’m also interested in Patriotic Millionaires, which Avi founded.
Also worth checking out: Jeff Atwood’s Stay Gold, America and Launching The Rural Guaranteed Minimum Income Initiative. So, not all of the 0.1% are The Enemy.
It’s not complicated
Around the world, governments are running up huge debts and cutting back social programs because the taxation revenue doesn’t come near the amount it requires to provide a livable society. So the choice is stark: Cut and slash deeper (read: starving beggars) or find more money. There’s lots of money out there basically just playing financial games; it needs to be put to work doing something useful.
This package of ideas should be easy to sell to voters. Of course, resistance will be ferocious and extremely well-funded. But the currently-winning side in our class war is actually a soft target. Target for what weapon, you ask? Democracy. No need for tumbrils and guillotines. Yet.
Corey’s Captives 26 Apr 2026, 7:00 pm
That’s James S.A. Corey, which is to say Daniel Abraham and Ty Franck, and their new series The Captive’s War, an in-progress work comprising 2¼ or so novels. The Coreys are of course best-known for their deservedly wildly popular The Expanse series and the subsequent success of the streaming-video version. The new series is… different. If you’re wondering whether or not you should wade in, the following is for you.
Minor and meta spoilers
Don’t worry, you can go on reading this even if you plan to read the books. Here’s a spoiler that has appeared in every public mention of the book, which I’ll give away with a quote from page 102: “I think some important scientific questions have finally been answered. Alien life exists, and they are assholes.” Which is to say, it doesn’t go well for the humans.
Now for the meta-spoilers. The novels are The Mercy of Gods and The Faith of Beasts, then there’s a novella, Livesuit. I found The Mercy of Gods a bit of a grind, and if that’s all I’d read I would have been pretty negative about this project. There is a major, major reveal partway into The Faith of Beasts that changed my whole outlook on the series; it makes the storytelling velocity really pick up. It’s a little annoying that Livesuit was published between the two full novels because it only really makes sense if you’ve finished both of them. So do like I did, and read the novella last.
I have to ask why the Coreys couldn’t have pulled the curtain aside a little earlier on. And while I’m griping, let me add that the sped-up storytelling runs into a big honking cliffhanger ending at high velocity. Harumph.
My take-away
It could go off the rails but if they can maintain their Expanse form, I suspect this series is going to be pretty great. The characters are fun to know and the narrative revolves around the great mother of all trolley-problem ethical challenges, which was not nearly resolved at cliffhanger-ending time.
Those of us who are fussy about the plausibility of future technologies (hey, Charlie Stross) should avert their eyes from the Coreys’ fairly low-effort attempts to explain how the aliens and humans in this story accomplish the things they do. Doesn’t bother me much, though.
Having said all that, this series is not cheerful stuff; I do not recommend it to those who, like many in these troubled times, are having trouble seeing the bright side of, well, anything.
Will I read the next volume?
Yep, no hesitation. And they’ve already started working on a streaming version. Unfortunately it’s going to be on Amazon Prime, which I haven’t missed since unsubscribing a couple years ago. Getting this thing on the screen is going to be an extended, difficult, task. There are multiple species of aliens that the show is going to have to absolutely nail, with emotional credibility, for the story to work. Don’t hold your breath.
Spring Evening 13 Apr 2026, 7:00 pm
On impulse, Lauren and I went out for a short walk — around just a few blocks — as the grey Spring afternoon shaded to dusk. On a second impulse, I grabbed the camera on the way out the door.
In our local community garden, here’s (I think) a chard.

That was in Vancouver’s Mount Pleasant park, small but nice and apparently never not used. Also this old blackened fruit tree, we’re a bit past the fruit-blossom peak for this year. Nice to see I’m not the only old citizen trying to brighten things up.

Now we’re walking up a locally-main street called Main Street or “The Main” if you’re trying to sound hip. Someone put work into that window! I’ve bought my daughter a couple of cool birthday presents from the store behind it. My thanks to the building across the street for providing a dark background reflection.

Back to the next block over from ours. A while ago a bunch of people were building little fairy/elf/hobbit villages at the bottoms of the big old trees. This isn’t that. What is it?

The colors of the natural surfaces are real.
Cameras
When I shot these, it was getting dark but I didn’t think much, mostly just pointed and shot. (Fiddled with the aperture dial a bit.) Then I came home and pulled them into Lightroom and didn’t need to do really anything about colors. A bit of contrast and highlights here and there. Oh, and fairly brutal cropping, especially on that fruit-tree-flowers pic. Because like I said, I didn’t think very much when I was shooting and I didn’t have to because on a Twenties camera you don’t.
I could take that heavily-cropped fruit-tree picture and print it big enough to occupy any domestic wall in your place and yeah, there’d be grain but it wouldn’t bother your eyes.
Anyhow, modern cameras are pretty great. The lowest ISO in today’s set is 2500 and the highest is 6400; the apertures range from 2.8 to 5.6. Bet you can’t tell the differences. My camera is a reasonably modern Fujifilm but not remotely bleeding-edge in camera tech. (Note: 35mm F1.4, now all the Fuji fanfolk are smiling and nodding.)
Anyhow, there are very very few photographers for whom the camera they carry is the limiting factor in the goodness of their pictures. Certainly not me.
Consider getting a camera. Used is fine, anything built in the last five years, maybe more, will effortlessly take brilliant pictures in almost any conditions. Sure, your phone can take great shots too, but the feeling of walking along with something that fits your hand and you only have to press one physical button once, that feeling, it helps you see the good pictures when they happen.
Then go out after and take a walk in the Spring dusk.
Password Manager Angst 9 Apr 2026, 7:00 pm
Our family has used 1Password for many years. Most recently 1Password 7, now at least three years out of date. We didn’t want to upgrade to the latest version, went looking for alternatives, and have been exploring Bitwarden. The best choice isn’t obvious; here’s the story thus far.
Important note: I suspect that most-to-all of the people reading this already are using a password manager. If you’re not, please, PLEASE start now. Your browser probably has an OK one built-in, which is much better than nothing. Here is a good write-up on the basics.
Our needs
They’re not fancy. The house contains Macs and Androids and Windows and an iPad. We have hundreds of accounts (some require an authenticator) and a basketfull of secure notes: Government-ID numbers, recovery codes, and so on.
1Password7 and 8
1Password had this nice feature where you could sync between devices without involving any 1Password servers, in a variety of ways. We used one of those and liked it. 1Password8 insists on storing your data (encrypted, more on that later). That always bothered me because, obviously, that repository is a top-priority juicy target for all the bad guys, who range from employees of the Chinese government to geeky narcos.
So we’ve been ignoring 1Password’s increasingly plaintive reminders that we were using years-out-of-date software and chugging along with version 7. But, early this year, they broke our sync mode on the Android app and were pretty blunt that the only way to get it back was to go to 1P8.
Alternatives
There are plenty of password managers (Let’s just say “PMs”) out there, but as a regular scanner of the landscape, it seems to me that 1Password (hereinafter “1P”) and Bitwarden (“Bw”) stand out as leaders. The rest of this piece will focus on those two. If you think I’m wrong, say so below but also please say why.
Note that Bw comes in two flavors: That offered as a subscription service by the company of the same name, or as an open-source software suite you can build and run yourself.
This is not to say that the PMs that are starting to appear built-in to browsers and OSes are worthless or unimportant, just that some of us need a little more.
The threat models
Two are obvious. The first is incompetence, like for example LastPass, who apparently left the doors more or less wide open to those bad guys I mentioned a few paragraphs ago. Complete horror-show.
The second is legal compulsion, where a government applies pressure to a PM provider to cough up our secrets. Anybody who thinks governments won’t try is fooling themselves, because they’ve repeatedly said they want to, and are eager to pass ill-considered legislation such as the CLOUD Act. So we care about that aspect a lot.
1P vs Bw: Security
I think they both have acceptably-good security postures; check out Bitwarden Security Whitepaper and About the 1Password security model.
Both of them offer to host your data outside of the US, specifically in Canada or the EU.
But it doesn’t matter that much if a bad guy or bad government gets their hands on your password store; what matters is whether or not they can decrypt it. I’m not an infosec professional but I know some and listen to them, and both those security postures give me a good feeling. It’s not an accident that they’re pretty similar.
The actual threat isn’t so much that an adversary cracks the crypto; that’s very unlikely. It’s that they find a way to force a PM vendor to build a back door into their software to get access to keys and passwords. For that reason, it would warm my heart if either or both of Bw and 1P were to post a Warrant Canary.
But I’m going to give Bw a very slight edge. First, because of the fact that you can build and run it yourself, if you’re willing to take responsibility for operating a server with strong security requirements. (I’m not.)
The source being open potentially offers a second, and more important I think, advantage: If they were able to get a Reproducible build working, you’d have assurance that the code you can download is the one their service is running. Which reduces the attack surface. (Mind you, not to zero.) Reproducible builds are hard, but if they did that, it would make a difference to me.
On the other hand, Bw’s software development process embraces GenAI generally and Claude specifically. At this stage in the growth of those technologies, this sends a chill up my spine. To be fair, 1P’s website shouts that it’s just the thing for agentic security, whatever that means. And we don’t know anything about 1P’s internal software-dev process.
1P vs Bw: Fit and finish
1P wins this one. The problem is, do they always pop up when needed and never when they’re not? Can they fill every login field that needs filling? Does the popup show you just what you need and nothing extraneous? I’ve used both and 1P is just better.
Business issues
This one is also pretty well a saw-off. Both of them have taken substantial chunks of VC money and thus are going to come under relentless pressure to enshittify. I worry a little less about this because from what I read, there’s not much lock-in.
Personal experience too: I recently did an export of everything out of 1P and into Bw and it all Just Worked, albeit putting all my stuff into a folder named "No Folder" that I can’t figure out how to rename.
Both Bw and 1P are subscription-only, at prices that seem fair to me.
Death and recovery and pen and paper
As I was reading up on this stuff, the issue of recovering access to your PM after it had been lost came up a couple of times. Here’s a scenario where that could be really important: I die. And then my wife needs to get access to bank accounts and business emails and so on.
Somebody (I’ve lost the link) was horrified that one of the PMs suggested writing the password down on a piece of paper as a last-resort measure, but I’m here to tell you that they’re wrong. My wife has an envelope containing a piece of paper on which appear the passwords for my PM and Mac, my mobile-phone PIN, and a very small number of other secret things she might really need if I’m suddenly gone. I have no idea where she put it, but she’s really smart so I don’t worry.
You should probably do something like this too.
What will we do?
We’ve paid for a year’s worth of both Bw and 1P. At the moment, we’re leaning to 1P because it’s a little more polished. Which matters because my PM is something I use many times every day. Also they’re somewhat Canadian.
If you think we’ve missed something, please do let us know.
Long Links 24 Mar 2026, 7:00 pm
This will be the 30th Long-Links outing. I’m 100% sure that there does not live a human being who has looked at all those Links, but my logfiles say that quite a few of you, Dear Readers, at least take the time to open one occasionally. All aboard!
Sadly, more than half the Long Links, this time out, are about AI. I almost decided to bury the piece but, whatever you or I think, the subject matters. And the ones I posted are a tiny fraction of those I read (or tried to) and I think are useful and not immoral.
But, let’s put all the non-AI stuff at the front so you can stop reading partway through if you’ve just had enough of that stuff.
Not about GenAI
Paul Ford has, after a lengthy gap, started writing again at ftrain.com. Excellent! Go there any day and there’ll almost certainly be something good at the top of the page. He’s a technologist and, yeah, writes about AI sometimes, but Warp and Woof is about dogs and their people. Charming.
I think most people who aren’t ultra-wealthy now agree that inequality is currently a central problem of our society. But it would be nice to put some numbers behind that assertion. Here is a conversation between Paul Krugman, Nobel-prizewinning economist, and Gabriel Zucman, a French specialist in the subject and frequent Piketty collaborator. Now, there are quite a few paragraphs up front of talk about general macroeconomic issues and comparisons between the US and Europe, which I enjoyed reading. And then inequality; here’s Zucman: “And so everybody now understands what was long understood for centuries, very much including in the West, which is that extreme wealth is never virtual, it is always extreme power.”
CO2 densities in Parts Per Million are a good measure of how full your inhalations are of others’ exhalations. And thus of how likely you are to catch something by breathing. Especially, Covid, which everyone with a half a brain knows is not nearly over. Anyhow, A. Grieve-Smith offers Nine observations from carbon dioxide monitoring: “I’ve been checking carbon dioxide levels for over three years now, and I’ve started to see patterns.” This piece could save your life, and that’s not a metaphor.
Patrick McKenzie, who writes Bits About Money, has an icy-cool style and this Link could be a Little Less Long, but I learn interesting things every time I read one of his pieces. Fraud Investigation is Believing Your Lying Eyes launches from the Minnesota child-care fraud story, but is mostly, as the title suggests, relates the conventional wisdom (which I didn’t know) about how to go sniffing around for in-progress fraud. From which “As a fraud investigator, you are allowed and encouraged to read Facebook at work.”
Hari Kunzru has written good books and is a former London native. Harpers gave him an assignment: Walk around and write about the city, thus Another London: Excavating the disenchanted city. It’s a tour through time as much as space — London, obviously, is history-drenched — and not just politics and power either, but arts and ideas. The writing is beautiful. It’ll take a chunk out of your day but the trade-off is good.
Here’s something beautiful: The HTML Review. Now I want to publish there, but I’d have to up my writing game.
Lankum
They’re an Irish band I just discovered, courtesy of Qobuz. The music grows out of traditional Irish acoustic folk. They play old and new songs and throw in a heavy dose of snarl and drone. Some of the chords are like rotated model augmented 11ths or some such, scratchy around the edges but helped with an itch I hadn’t known I had. Terrific musicians. Here’s Hunting the Wren. I might get over-excited and fly to Ireland to see them.

Tech, but not GenAI
Sebastian Pipping is, among other things, an Open-Source software developer, with whom I’ve collaborated. His recent Learn from me! begins “Not too long ago, someone literally asked me what they "could learn from me", and that question has stuck with me since.” So he offers a few candidate lessons. What a nice idea! What could people learn from you?
Filippo Valsorda, another OSS dev, is particularly interesting because he and a few partners have apparently figured out how to make a living from their work. He recently published Turn Dependabot Off and I’m not going to offer a word of explanation because if you understand the title I guarantee you’ll be interested in the piece. (I’m terrified of Dependabot.)
It seems like every day I hear from another person who’s trying to get their personal lives off Big Tech. Me too. So… In The Verge, How to un-Big Tech your online life. And from Paris Marx, Getting off US tech: a guide. We are in the early stages of de-Googling our family life, so this stuff is super useful. I expect to see more of it.
Amazon polemics, maybe a little AI
I don’t loathe Amazon any more nor less than the rest of the Big Techs, but boy are there are a lot of people publishing diatribes against the company. Not sure I understand why. But, worth reading.
In How Amazon Dies: A Possible, Maybe Likely Future Mark Atwood predicts that the infestation of amazon.com with highly-profitable advertising is a perhaps-fatal blunder. What’s maybe more interesting is that he points out several potential Amazon alternatives that don’t suffer from that same infestation; they hadn’t occurred to me.
And from a year ago, Cory Doctorow’s The future of Amazon coders is the present of Amazon warehouse workers introduces the “shitty technology adoption curve”. I missed this piece at the time but boy, is it easy to believe.
Finally, reading Writing Crystalized Thinking At Amazon. Is AI Muddying It? angered me. While I have no remaining respect or affection for any of the Big Techs, I enjoyed my time at AWS and part of it was the writing culture. I think the Way Of The Six-pager is the best business-process innovation I witnessed in my working life. If Amazon really is slopifying it, I predict disastrous outcomes.
OK, here’s the AI stuff
My own position, just to be clear: There are going to be LLM applications in a few domains here and there, and one of them is software development, but they won’t be nearly big enough to damage earth’s climate any further, nor to prevent the bubble from popping. That said…
Let’s do the worst first: Write-Only Code lays out a genuinely frightening future. Quote: “I was maniacally insistent that any proposed change to our SDLC (software development life cycle) be evaluated first through the lens of developer velocity.” I think I’d rather not go there.
Most of us who watch the space, and have no idea where it’s going or what the future holds, are I think particularly interested in Anthropic’s Claude. If you’re one, you’ll probably enjoy What Is Claude? Anthropic Doesn’t Know, Either.
It’s probably not that GenAI is intrinsically immoral. As Karl Bode writes, The Problem With AI Is Shitty Human Beings. I covered some of the same territory last year in The Real GenAI Issue, but Bode is excellent: “…the grand vision of modern automation's benefits can never materialize if its stewards are foundationally fucking terrible human beings disinterested in the contours of empathy. If we're not talking prominently about that, we aren't really talking at all.” (Emphasis his.)
One of the things that shitty people do is lie. Like for example charismatic leaders of AI “startups” valued in the tens of billions. But then so do the less-visible, which provoked Kyle Kingsbury A.K.A. Aphyr to write Trudging Through Nonsense. It’s sad and angry but I think usefully so.
Armin Ronacher is not bursting with rage, but he is skeptical about all the right things in Some Things Just Take Time. Quote: “There’s a feeling that all the things that create friction in your life should be automated away. That human involvement should be replaced by AI-based decision-making. Because it is the friction of the process that is the problem. When in fact many times the friction, or that things just take time, is precisely the point.”
For another cool-voiced critique, here’s Rishi Baldawa: AI Mandates Manufacture Noise. While I’m not entirely a burn-it-all-with-fire GenAI foe, the “boss mandate” always struck me as dumb, and Rishi spells it out clearly and simply. It’s really good, so here are a couple of quotes: “But those not in the weeds had no way to know any of this because… well they aren’t in the weeds. So they feel compelled to solve their information gap with a policy hammer.” and “As said before, none of this is revolutionary and that’s sort of the point. AI is a ’mirror and multiplier‘. It intensifies whatever was already happening.”
That’s all
Let’s really hope the bubble bursts soonest. Because when the money goes away, so will a lot of the shitty people.
Nash Burns Saves the Day 20 Mar 2026, 7:00 pm
What happened was, soon after New Year’s, friends and colleagues in the UK and Germany started letting us know that their emails to us were bouncing. Our “textuality.com” family domain is a Google Workspace (or whatever they call it this year) for email and docs and so on. Its Web presence, including DNS, has for many years been handled by a local outfit I’ll call “CWH” for some absurdly low monthly price, and has been trouble-free.
So, what could be wrong? We investigated and discovered that Google was offering a new-and-improved MX-record option, although they emphasized that the old setup should still work. Anyhow, we installed the New Thing and it didn’t help.
So, we filed a ticket with CWH tech support and somebody got back to us pretty quick, saying they’d changed a firewall
setting that was blocking connections to Germany. I detect the scent of GDPR, but whatever.
Euro-email: Bounce, bounce.
CWH: Probably an MX-record issue, and we should wait for DNS propagation. Several days passed and
bounce, bounce, bounce.
Us: “Not DNS propagation.”
CWH: “Still could be.”
So we VPN’ed to Germany and discovered we couldn’t ping Textuality’s IP address. Smells like a firewall to me. We told CWH that.
CWH: We have made some changes to firewall settings.
EMail: bounce, bounce, bounce.
VPN+Ping: Request timeout, request timeout, request timeout.
CWH: Try traceroute?
VPN+Traceroute: 14 hops, no joy.
CWH: Your VPN settings must be wrong. Here are instructions to use Windows PC VPN correctly.
Us: Thanks but no.
CWH: Your MX records are configured incorrectly.
Us: No, they are correct per Google guidance. We sent an email beginning
“Please believe us.”
CWH: It must be DNSSEC. Check to see if your registrar implements DNSSEC.
Us: We are using your DNS servers.
CWH: Perhaps your registrar is broadcasting an old record?
Us: Our registrar doesn’t do DNSSEC.
At this point we consulted a friend who’s an expert on DNS and Email and even DNSSEC. He verified that not only could you not ping Textuality from Germany, you also couldn’t ping CWH or its name servers. Firewall firewall firewall!
CWH: “I did test the site access using a 3rd party application, and it seems to be accessible on all parts.”
Us: Look at the
output, it shows we can’t be reached from anywhere in Germany.
Also, for all the remaining messages in the email trail, we prefixed our input with bold face extra-large text reading: Systems located in Germany cannot ping Textuality.com’s IP address, nor can they ping the IP addresses of textuality.com’s designated name servers. This is the problem.
CWH: Let’s try migrating you to a different server; try pinging these hostnames.
VPN+Ping: Nope.
CWH: Are you sure it’s not your VPN settings?
Us: Are you sure it’s not your GDPR settings?
CWH: Raising your issue to Tier 3.
20 hours pass, then we get email from:
Nash Burns!
…who said “This has been fixed.” It was. Nash’s email signature was “Nash(Rajaneesh) B”. What a great name, though. Thanks, Nash.
Am we mad?
Not really. Consumer-facing tech support is hard. None of their suggestions were unreasonable. Doing GDPR correctly is hard. They’ve been just fine for years and were having a bad week. Could we expect better from any of CWH’s local competitors? Probably not.
It wasn’t funny at the time, but looking back, it kind of is.
Pure Sound Please 16 Mar 2026, 7:00 pm
This last weekend we attended a concert entitled Lenten Reflection at Vancouver’s Catholic Holy Rosary Cathedral featuring the Belle Voci vocal group and the Cantare Super Orchestram early-music band. The music was fine and it was the most beautiful sound I’ve heard in a long time. Twenty-two months, to be precise (see below). And so I get to report on good music and yell at production people.
A cathedral is a nice place for a concert!

The concert opened with just the singers, their voices drifting down from a high place behind us, a balcony or choir loft. There was no incremental accompaniment and no amplification; the music flowed from vocal cords to eardrums — not directly, of course, there was lots of reflection and reverberation introduced by the Cathedral space. The singers were polished and expressive and the sound, drifting through the vast space, beyond exquisite.
They sang a lovely piece by Byrd (1539-1623). Then the instrumentalists played a number by von Biber (1644-1704) while the singers snuck downstairs. Joined, they performed Bach’s BWV 229 and 150, then pieces by Pergolesi (1710-1736) and Steffani (1654-1728).
The Bach pieces, as usual, had more music in the music, but the others were also fun. It was a small ensemble: In the choir, five sopranos, five altos, a countertenor, four each tenors and basses. The band had five baroque violins, a baroque viola, a baroque cello, a violone (think, string bass with frets), a baroque bassoon, and a player doubling on harpsichord and organ. Thus, an ensemble quite likely not too much bigger or smaller than the ones playing this music in the 1700s, when it was new.
That sound
Once again, the sound was something special and yeah, the musicians were excellent, but for me, the key thing was the lack of amplification: vocal cord to eardrum via cathedral. It’s always seemed obvious to me that you can’t run music through a bunch of electronics and speaker mechanics without changing it; if only spatially, with the sounds coming from speaker diaphragms located somewhere away from the human musician. To my ears, there is a fragile magic in pure unamplified sound. I lack the words to describe the difference but it’s not subtle.

Does this mean that everything was perfect? No; the choir was a little bit male-heavy; some of the soprano and especially alto lines were part-hidden behind the massed male voices. Also, the bassoon was right at the front of the stage; While the playing was fine, it felt as though it were musically, not just physically “in front of” the band and singers.
Both of these could have been fixed, by telling the men to take it down a notch or having one or two fewer of them. And by moving the bassoon back to the usual woodwinds spot behind the strings. Still, these were very minor imperfections.
Oh, and the performance and sound of the bass line on that violone was absolutely awesome; clearly audible as a thing on its own while it wove all the other musical threads together.
I’ve discovered that few classical musicians share my passion for unamplification. I hear things like “I want a full sound or “The soloists need to cut through the orchestra.” Which, well, OK, but somehow people managed to accomplish those things for centuries, before amplifiers and speakers were invented.
22 months?
That’s since May of 2024 when I took in the Tedeschi-Trucks Band, whose music couldn’t be more different from anything called “Lenten Reflections”: electric not acoustic, profane not sacred. But crystal clear and perfectly balanced sound; so much better than most electric bands achieve.
My sincere thanks to the musicians and their leaders for a lovely experience. And my message to everyone co-ordinating and leading live music performances: Of course the first priority has to be the quality of the music, but think about the sound and try to be better. Better than than most performances manage, these days.
We know it’s possible.
Because Algospeak 5 Mar 2026, 8:00 pm
Recently I read Because Internet by Gretchen McCulloch and Algospeak by Adam Aleksic. The language we speak (and text) to each other is at the core of who and what we are, and the Internet is the strongest among the forces that channel and fertilize its growth. So there’s scope for plenty of books on the subject. Both books educated and entertained, one made me angry.

Because Internet (2019)
Its approach is historical and its voice fairly uninflected. It smiles and argues, but it doesn’t ROFL nor does it YELL AT YOU. The history is longer, perhaps, than most people reading this have been online (or even alive). Ms McCulloch goes back to the days of BBSes (“bulletin-board systems”) and ListServs and IRC. Some of the jargon and formulations of those days live on; you’d be surprised.
Here’s her table of contents.

The analysis is grounded in the formalisms of the author’s profession, academic linguistics. Nothing wrong with that.
Let’s look at a couple of her ideas, beginning with Chapter 1’s “Informal Writing”. A few of us, back in the late Eighties, noticed that computers in general and the then-nascent Internet in particular were driving a writing renaissance.
Before computers, a knowledge worker who had laboriously constructed essays in college quite likely wrote almost nothing for the rest of their working life. People talked face-to-face or on the phone, and dictated to secretaries. Written communication was seen as necessarily formal and disjoint from the way we spoke, or that we wrote in personal correspondence. Then, suddenly, everyone was sitting at a keyboard only seconds away from everyone else’s screen. McCulloch goes deep on this:
In the future, the era of writing between the invention of the printing press and the internet may come to be seen as an anomaly—an era when there arose a significant gap between how easy it was to be a writer versus a reader. An era when we collectively stopped paying attention to the informal, unedited side of writing and let typography become static and disembodied.
The internet didn’t create informal writing, but it did make it more common, changing some of our previously spoken interactions into near-real-time text exchanges.
From which all of this follows. It feels like a central insight. I suppose you could argue that centrality of informal text is fading in the face of short-form video. Maybe, it’s too soon to tell.
Then consider chapter 5, about emojis. Linguists obviously need to think about them because now they’re an integral part of written language. McCulloch’s insight is that they correspond almost exactly to gestures, the way we use our hands to add force to our speech. Obviously, for example, “👍”. Or when you’re talking about something completely loopy and you twirl your index finger by your ear? You meant “🤪”.
I offer the emoji story for flavor, an example of a linguist’s approach to what we’re doing to our language with our networks.
McCulloch has lots more of this stuff. I enjoyed Because Internet a lot, partly because I’m old and my memories stretch back to those BBS and IRC days and I had a front-row seat for the decades of linguistic seething and heaving. And also because I’m a Unicode geek.
Algospeak (2025)
The subtitle is “How Social Media Is Transforming the Future of Language”. OK, but… Social media is a fertile field for language evolution. Thing is, corporate social media discourse lives in the dire grip of the proprietors’ algorithms. And that’s where Adam Aleksic focuses. He treats all of them as a single opaque object, “The Algorithm”, which I think is fair because they all are designed with one goal: To maximize the effectiveness of human conversation at generating advertising revenue.
First, the Table of Contents.

Aleksic knows whereof he speaks: As “Etymology Nerd”, his aggregate following across TikTok, Instagram, and YouTube is over three million. He’s all about cool bits and pieces of linguistics, often Internet-specific usages. If I had the patience for podcasts I suppose his would be near the top of my list.
He really enjoys his work and has fun talking about some of Social Media’s more colorful linguistic extrusions; check that Table of Contents. I’m kind of old and I learned a lot about the words and emojis younger folk emit, and I think most folks, even those just out of their teens, would too. I’m on a Discord for a Major League Soccer team’s fans, and while it’s totally all-ages, I can say I am regularly less mystified than I was before I read Algospeak. For example, now I know what it means when someone tosses “💀” into a chat. Do you?
Aleksic isn’t averse to a little history himself. Looking back over the successive online-jargon volcanoes, he argues convincingly that two stand out as extra productive. First of all, the short-lived (but hot stuff at the time) Vine video platform. Second, the incel cesspool; sad but (apparently) true.
The Algorithm
Remember, it’s all about what advertisers want. And wow, do they ever want a lot of things. I’ll just touch on a few of Aleksic’s points.
First of all, they don’t want to find themselves next to downers. So if you want to talk about death or suicide or rape or racism or rage, you need to fool The Algorithm. Thus “unalive” and many other dodges. Of course, The Algorithm learns about them so you have to keep dodging. Neither side of this struggle can stay ahead for long.
Here’s another thing I didn’t know: Apparently written Chinese is particularly rich in techniques for euphemizing, making it easier for users of that language to evade, for a time, The Algorithm.
Partitioning people
Another big thing The Algorithm likes is grouping people into smaller and smaller baskets based on interests, generations, and many other criteria. This is because advertisers can aim very specific campaigns at just exactly the right cohort of people who are likely to buy what they’re selling. Here’s a quote; See how the language fills in behind advertisers’ pressure?
It doesn’t matter how much I label myself. If I’m a demisexual goblincore Gen Z Swiftie, I guarantee there are still others like me. The only thing these labels really change about me is that they make me easier to classify and market to. Ironically, true individuality may come out of a lack of labels and stories, because there’s greater freedom of expression with a blank slate. If everybody’s the “main character,” then nobody is.
Algospeak, unlike Because Internet, doesn’t limit itself to written language. One of its most compelling studies concerns the vocal techniques of podcasters and YouTubers. The finding is simple: It’s hard to build and hold an audience for your show unless you sound like MrBeast. No, really.
Anyhow, they’re both good books. Because Internet educated and entertained me. Algospeak is way more intense, intentionally more like the subject it addresses. Also it made me angry. I am a lover of human language and of its patterns of growth and mutation and simplification and complexification. Linguistics is one of the disciplines I regret not having chosen.
Aleksic makes it clear that there’s an amusing narrative about how the people living and speaking in the shade of the Algorithm can never defeat it, but they can still manage to get their messages across. But they shouldn’t have to struggle!
In fact, a few million of us have found a place to talk to each other that isn’t in The Algorithm’s shadow: Decentralized social media. Specifically the Fediverse (what people mean when they say “Mastodon”) and maybe the ATmosphere (same for “Bluesky”).
I want to see how language grows in a place where new forms arrive when they’re needed, to say new things that need to be said. Not to either serve or resist The Algorithm.
Kansas and AI 27 Feb 2026, 8:00 pm
Block announced that it’s cutting 40% of its workforce. It didn’t say it was replacing those people with GenAI. Not out loud. Jack Dorsey did say “I believe the majority of companies will reach the same conclusion and make similar structural changes.” Wall Street loved it, bidding up the share price by 24%. Which reminded me of Kansas in 2010.
The Kansas Experiment
As long as I can remember, a certain class of right-wing evangelists has preached that cutting taxes would stimulate business growth and everyone would come out ahead. There are a couple of problems with this theory. First, mainstream economists almost universally think it’s just wrong. Second, most of the people pushing it are rich and would benefit from the cuts.
Anyhow, in 2010 US Senator Sam Brownback won the race for governor of Kansas on what was then called the “Tea Party” program: Prosperity through tax cuts. Tea-party Republicans also won a large majority in the state legislature. Unsurprisingly they immediately did what they said they were going to do: Slashed a wide variety of taxes, some to zero.
The predicted prosperity failed to happen. The state government’s revenue plunged and it had to dig deep into rainy-day reserves just to keep the doors open. There were brutal cuts to policing, road repair, and schools. Also a nasty feedback loop: As the state’s fiscal position worsened, its credit rating fell and interest rates rose, leading to yet more brutal austerity measures.
Another result was that affluent Kansans made out like bandits; the cost of running the state was substantially transferred to the less financially fortunate.
In 2017, the legislature threw in their cards and repealed the tax cuts, overriding Brownback’s veto.
While this was a terrible experience for most Kansans, it is historically useful, because whenever you encounter a tax-cut nut (probably self-interestedly wealthy) you can say “But, Kansas!” Having said that, there are still plenty of those nuts, and they’ll tell you that the Kansas experiment failed because of one fine-tuning effort or another. That’s a position that’s hard to defend, though.
Sidebar: Trans oppression too
Before I move onto the AI angle, I gotta pause to acknowledge this week’s news story about the Kansas government’s vicious, brutal, and ignorant assault on trans people. To be clear, I think the shitty people who hate trans folk are aren’t necessarily the same shitty people as the shitty people who don’t want to contribute to the public good. But, something about Kansas seems to attract both flavors.
The GenAI experiment
The core value proposition of contemporary AI technology is exactly what Dorsey seems to think: Fire half your employees and profits will soar! If that’s true, the trillion dollars or so invested so far will seem like small potatoes. Since we don’t know if this will actually work, anyone who actually does it is conducting an experiment. Just like Sam Brownback did. Unsurprisingly, the investor class loves this experiment and is putting their money on it working.
To be fair, voices have been raised to argue that the tech sector is a special case: That following on feverish over-hiring during the Covid lockdown, they need to slash headcount anyhow, and are using AI as an excuse. For example John Gruber.
I personally am unconvinced, but even if they’re right, it’s irrelevant. The shareholding class won’t be able to see past that 24% payoff. So as of today, they’ll be yelling at every CEO on the planet to start pulling the mass-firing trigger. Or else.
I think I know how the experiment will turn out. Just like in Kansas, it’s not going to be fun.
Crocuses of 2026 24 Feb 2026, 8:00 pm
I’ve run early-spring pictures of these little purple guys almost every year since this blog’s birth in early 2003. Except for last year. Because we moved and the new place didn’t have any. Only now it does, and they’re (just barely) up. [Update: Up and open, too.]

Long-time followers may note that they’re pale and fragile compared to the exuberant blossoms of previous years. Not sure why, but our new place faces north and there’s this enormous White Ash tree right in front of it, so they’re not getting as much sun as at the south-facing former joint.

And also this is their first spring. We bought the bulbs and hired a professional with the right tools to jam them into the earth last autumn, between the big tree’s roots. So they really haven’t had a chance to get their own root systems going.
And finally, it really is the first day that’s bright and warm enough to get out the camera. Maybe they’ll be better in another few days. And quite likely next Spring.

This would be the place to introduce whatever metaphor this year’s blossoms, fighting their way through the leaf cover in chilly air toward the sun, fit into, but I’m not gonna.
I, like many, am not dealing very well with what I see when I look at the world in either the big or the ultra-local landscapes. The world in tough shape and its worst people are making it worse. People I love are in ugly corners and not finding help.
But you know, the flowers, in their low-key way, look great and so does the tree, still in wintersleep. Today the sun was shining on them. It’ll be warmer and nicer soon.
Metaphors can go to hell. It’s just late-winter light on pale violet petals. Enjoy the moments you have with it.

Update: Now open for business.
Open Source and GenAI? 16 Feb 2026, 8:00 pm
I’ve been puttering away on my Quamina project since 2023. In the last few weeks GenAI has intervened. Quamina + Claude, Case 1 describes a series of Claude-generated human-curated PRs, most of which I’ve now approved and merged. Quamina + Claude, Case 2 considers quamina-rs, a largely-Claude-driven port from Go to Rust. Both of these stories seem to have happy endings and negligible downsides. So empirically, I can apply LLM technology usefully to software development. But should I?
Conclusions 1: Burn it with fire?
Let me be clear: In the big GenAI picture, I’m a contra. Why? I’ll pass the mike to Baldur Bjarnason, my favorite among GenAI’s blood enemies.: “AI” is a dick move. His tl;dr is something like “GenAI is environmentally devastating and has the goal of throwing millions of knowledge workers onto the street and is being sold by the worst people and is used for horrible applications and will increase society’s already-intolerable level of inequality!” To which I reply “Yes, yes, yes, yes, and yes.”
At the end of the day, the business goal of GenAI is to boost monopolist profits by eliminating decent jobs, and damn the consequences. This is a horrifying prospect (although I’m somewhat comforted by my belief that it basically won’t work and most of the investment capital is heading straight down the toilet).
But. All that granted, there’s a plausible case, specifically in software development, for exempting LLMs from this loathing.
First of all, size. JetBrains thinks that the world has 21 million or so software developers, i.e. less than 1% of the earth’s working population. Vanishingly small in the context of the lunatic tsumani of LLM overinvestment. Training and operating the models required for a market this small is rounding error measured on the Great GenAI Overbuild scale. There aren’t enough geeks to create a detectable bump in the global carbon load.
Another odious aspect of LLMs is RLHF, “Reinforcement Learning From Human Feedback”, which relies on underpaying Third-Worlders to polish the models’ outputs. My guess is that much less is required for code-oriented LLMs. The combination of the compiler and your unit tests provide good starter guardrails. Then skilled professional intervention is required to deal with the remaining misfires, as with those Quamina PRs.
Finally, it seems making billionaires into multibillionaires is intrinsic to GenAI dreams. But software-development tools won’t do that. Once again, the market is just too small. But even if it weren’t, consider this from Steve Yegge:
For this blog post, “Claude Code” means “Claude Code and all its identical-looking competitors”, i.e. Codex, Gemini CLI, Amp, Amazon Q-developer ClI, blah blah, because that’s what they are. Clones.
(GenAI, overbuilding wherever you look.) None of these products have moats and the chance that any of them become extractive monopolies is about zilch. Nobody’s ever built a major cash-cow on developer tooling
One reason is (*gasp*) Open Source. Does anybody doubt that in the near future, there will be entirely open-source versions of what Yegge means by “Claude”?
So, if you want to condemn the use of GenAI in software development, I think you need arguments other than the fact that it’s also being promoted for societally-toxic business purposes.
I have a few. But stand by, let me push that on the stack and turn to technology for a bit.
Conclusions 2: Engineering sanity?
Question: Can LLMs even participate in quality software engineering? Baldur doesn’t think so: “The gigantic, impossible to review, pull requests. Commits that are all over the place. Tests that don’t test anything. Dependencies that import literal malware. Undergraduate-level security issues. Incredibly verbose documentation completely disconnected from reality.”
I’m not saying that these pathologies can’t or don’t happen. But in my personal experience with Quamina, they didn’t. (Mind you, it’s a hobby project.)
And when they do happen, I would assume that mature open-source projects will use a network of trust, as big operations like Linux already do. PRs that don’t have the imprimatur of someone known to be clueful will be ignored. When I saw the first of those incoming Quamina PRs, I took the time for a serious look because I knew Rob and had seen evidence that he was technically competent. If I see an incoming PR that’s nontrivial and from some rando and doesn’t pass a 120-second sanity check, it’s unlikely to get any more attention.
In fact, some essentials don’t change. If you’re not requiring that PRs be clean and test coverage be good and code reviews not be skipped and dependencies be curated, you’re going to get a lousy result whether the upstream code is coming from a human or an LLM.
But it’d be naive to think that a big change in the shape of that upstream isn’t going to affect the profession.
Bottlenecks
Speaking from personal experience, reviewing the PRs from Claude&Rob was neither faster nor slower, easier nor harder, than what I’m used to pre-GenAI. The number of my disagreements with the diffs, and the amount of arguing it took to resolve them, was also about as usual. Which creates a big problem. Because if we can generate code a whole lot faster but review doesn’t speed up, all we’ve done is moved the bottleneck in the system.
Speaking of which, Armin Ronacher offers The Final Bottleneck, from which: “When one part of the pipeline becomes dramatically faster, you need to throttle input.” Think about that.
Burnout
Meanwhile, evidence is piling up that LLM-based software development is driving developers to overwork and burnout. Here’s a cool-eyed take from Harvard Business Review. Then there’s Steve Yegge’s frantic, overly-long The AI Vampire. But my favorite, and I think a must-read, is Siddhant Khare’s AI fatigue is real and nobody talks about it. From which: “AI reduces the cost of production but increases the cost of coordination, review, and decision-making. And those costs fall entirely on the human.”
The argument we’re hearing is that GenAI makes development more efficient. And more efficient is better. Until it’s not.
I’m not sure the profession I joined last century would attract me today. And on Mastodon, @GordWait said “At our office, we are noticing a huge drop in Comp Sci co-op applications. The next generation is convinced there’s no future in programming thanks to AI hype.”
Can and should
Here’s another conundrum. Suppose we can build a whole lot more stuff, faster. Should we? I don’t know about you, but I am regularly enraged at tools that work just fine popping up “wonderful new features” modals in front of what I’m trying to get accomplished. Also at damaging UI churn, driven by product managers trying to get promoted. It’s just not obvious that speeding up software development is, in the big picture, a good thing.
And I can’t help noting that every attempt to measure the productivity boost due to GenAI has shown zero (or worse) improvement. Of course, Claude’s cheering section will point out that those studies date to 2024 which is the stone age. Maybe they’re right.
Vampires
(In which I once again go all class-reductionist.) The real problem here is late-stage capitalism, and I think is best addressed in Yegge’s AI Vampires piece, from which I quote: “…dollar-signs appear in their [employers’] eyeballs, like cartoon bosses. I know that look. There’s no reasoning with the dollar-eyeball stare.” Yeah.
Thus the ancient question: cui bono? Assuming GenAI genuinely boosts productivity, who gets the benefits? Because the ownership class sure doesn’t think they should go to their newly-more-efficient employees.
But, what do I know?
I know that you gotta have test coverage or your software is an unmaintainable tangle of festering tech debt. I know you gotta have code review or your quality is on inexorable downhill drift. I don’t know how to build LLMs into a sane, sustainable software engineering culture. Nor what to do about capitalism’s AI Vampires.
And I absolutely do not believe the wild-eyed claims of 10× productivity gains, assuming we demand (as we should) that they’re sustainable at scale.
So, would I advise executives to tell software engineering shops to discard their culture in favor of vibe coding in the expectation of monstrous productivity wins? Nope. Vibe engineering, maybe. Centaurs, not reverse centaurs? Indeed.
But would I say “Stay away, don’t even look”? Nope. I’d probably suggest pointing the LLM at well-delimited non-strategic issues and optimizations, and emphasize no shortcuts on reviewing or CI/CD standards.
Also note that the GenAI apostles are at one in saying that this year’s tools are so much better than last year’s, and next year’s are guaranteed to be qualitatively still better! So why would you rush in and risk getting locked into soon-to-be-outmoded tooling?
Rob Sayre wrote “I would never bother to type out these patches by hand. But I read them all.” I probably wouldn’t have either and I read them too. And now Quamina is roughly twice as fast. Which is to say, I got good results on a hobby project. That’s not nothing.
But, also not conclusive. Once the AI bubble pops and we’ve recovered from the systemic damage, I think there’ll probably be a place for open-source LLM automation in developer toolkits.
But maybe not. Wouldn’t surprise me much, either way.
Quamina + Claude, Case 2 14 Feb 2026, 8:00 pm
Last time out I described a bunch of incremental-improvement Quamina PRs from a colleague working with Claude Opus. Today I want to talk about Rishi Baldawa’s quamina-rs, a Claude-based port of Quamina from Go to Rust. The next post is about where I stand on GenAI and code.
Anybody who cares about this kind of thing will appreciate Rishi’s write-ups, starting with The Agents Kept Going (also see Scaffolding for Agent Velocity). He doesn’t just say what he did, he draws lessons; good ones, I think.
Background
Rishi and I worked together at AWS, can’t remember the details, but after I left he took over what we called Ruler, now known as aws/event-ruler, Quamina’s ancestor. At the time I left it had been adopted by quite a number of AWS and Amazon services and various instances were processing, in aggregate, a remarkable number of millions of events per second. So he knows the territory.
As for quamina-rs, go read his blogs. I’ve got little to add, but here are a couple of juicy quotes: “…at some point while I was mindlessly kicking off these sessions, the agents started picking up open issues from the Go version and implementing them on their own.“ Also, “And I think that’s the thing worth saying plainly. It’s human to care. Agents don’t care. Automation doesn’t care. They need to be told what to care about, and even then they’ll misbehave the moment you look away…”
Both these stories ended with useful results. So empirically, you can get useful results by applying GenAI to the process of code construction.
Yay. I guess. But there are a lot of smart people who think this whole LLM-fueled coding direction is irremediably toxic. I’m not sure they’re wrong.
Quamina + Claude, Case 1 6 Feb 2026, 8:00 pm
With 47 years of coding under my belt, and still a fascination for the new shiny, obviously I’m interested what role (if any) GenAI is going to play in the future of software. But not interested enough to actually acquire the necessary skills and try it out myself. Someday, someday. Didn’t matter; two other people went ahead without asking and applied Claude to my current code playground, Quamina. Here’s the first story. I’m going to go ahead and share it even though it will make people mad at me.
Why share?
Because our profession’s debate on this topic is simultaneously ridiculous and toxic. No meaningful dialogue seems possible between the Gas Town-and-Moltbook faction and the “AI” is a dick move camp. So, I’m not going to join in today. This is pure anecdata: What happened when Rob applied Claude to Quamina. I’m going to avoid rhetoric (in the linguistic sense, language designed to convince) and especially polemic (language designed to attack). I promise to have conclusions before too long, just not today.
What happened was…
There’s this guy Rob Sayre, I’ve known him for many years, even been in the same room once or twice, in the context of IETF work. I’ve never previously collaborated on code with him. Starting in mid-January, he’s sent a steady flow of PRs, most of which I eventually accept and merge.
The net result is that Quamina is now roughly twice as fast on several benchmarks designed to measure typical tasks.
Technical details
The details of what Quamina is and does are in the
README. For this discussion, let’s ignore everything
except to say that it’s a Go library and consider its two most important APIs. AddPattern() adds a Pattern (literal or
regexp) to an instance, and
MatchesForEvent considers a JSON blob and reports back which Patterns it matched. It’s really fast and the
relationship is pleasingly weak between the number of Patterns that have been added and the matching speed.
Quamina is based around finite automata (both deterministic and nondeterministic) and the rest of this technical-details section will throw around NFA and DFA jargon, sorry about that.
For code like this that is neither I/O-bound nor UI-centric, performance is really all about choosing the right
algorithms. Once you’ve done that, it’s mostly about memory management. Obviously in Quamina, the AddPattern call
needs to allocate memory to hold the finite automata. But I’d like it if the MatchesForEvent didn’t.
Go’s only built-in data structures are “map” i.e. hash table, and “slice” i.e. appendable array. (For refugees from Java, with its dozens of flavors of lists and hashes, this is initially shocking, but most Go fans come to the conclusion that Go is right and Java is wrong.) In really well-optimized code, you’d like to see all the time spent either in your own logic or in appending to slices and updating maps.
In less-well-optimized code, the profiler will show you spending horrifying amounts of time in runtime routines whose names include “malloc”, and in the garbage collector. Now, both maps and slices grow automatically as needed, which is nice, except when you’re trying to minimize allocation. It turns out that slices have a capacity, and as long as the number of things you append is less than the capacity, you won’t allocate, which is good. Thus, there are two standard tricks in the inventory of 100% of people who’ve optimized Go code:
When you make a new slice, give it enough capacity to hold everything you’re going to be adding to it. Yes, this can be hard because you’re probably using it to store input data of unpredictable size, thus…
After you’ve made a new slice, keep it around, clear it after each input record, and its capacity will naturally grow until it gets to be big enough that it fits all the rest of the records, then you’ll never allocate again.
Those PRs
Background: Quamina is equipped with what I think is a pretty good unit-test suite, and multiple benchmarks.
I started getting Rob’s PRs and initially, 100% of them were finding ways along both of those well-trodden map-and-slice paths, in places where I hadn’t noticed the opportunity. They were decent PRs, well-commented, sensible code, no loss of test coverage. After I asked to see benchmark runs to prove the gains weren’t just theoretical, they started including benchmark runs. I’ve found a few things to push back on but Rob and I had no problem sorting those out.
At the end of the day I had no qualms about merging them, but I did find myself wondering how they were built. So I asked.
Workflow
Rob had told me right away on the first one that these were substantially Claude-generated. I asked him for his workflow and part of what he said was “I might say ‘let's do some profiles of memory and CPU on this benchmark, on main and on this branch.’ It will come up with good and bad ideas, then I pick them.”
Also: “What might be counter-intuitive is that I can context switch really quickly with it. So, you leave a comment, and I just tell Claude to fix that, because you are correct. Sometimes I go in and hand edit, but usually it gets close or perfect (what they call a "one-shot"). But I just have the conversation open, so I just pick up where we left off.”
Here’s a sample of Claude talking to Rob. You may have to enlarge it.

Not just the same-old
Then I got a surprise, because Claude and Rob spotted two pretty big improvements that aren’t on the standard list. First: To traverse an NFA, for each state you have to compute its “epsilon closure”, the set of other states you can get to transitively following epsilon transitions. I had already built a cache so that as you computed them, they got remembered. C&R pointed out “Epsilon closures are a property of the automaton structure, not the input data. Once a pattern is added and the NFA is built, the epsilon closure for any given state is fixed and never changes.” So you might as well compute it and save it when you build the NFA.
This is even better than it sounds, because (for good reasons following from Quamina’s concurrency model) my closure caches were per-thread, while the new epsilon closures were global, stored just once for all the threads. Not bad, and not trivial.
Second, when you’re computing those closures, you have to memo-ize the key functions to avoid getting caught in NFA loops.
I’d done this with a set, which in Go you implement as map[whatever]bool. R&C figured out that if you gave each
state a “closure generation” integer field and maintained a global closure-generation value, you could dodge the necessity for the
set at the cost of one integer per state. The benchmarks proved it worked.
As I wrote this piece, another PR arrived with a stimulating title: “kaizen: allocation-free on the matching path”.
Kaizen?
It’s the idea that you make things substantially better by successively introducing small improvements. We try to use the term to tag Quamina PRs that change no semantics but just make performance better or more reliable or whatever.
But GenAI is bad!?!
Yes, so they say. Go re-read that dick-move polemic.
But, I’m going to leave this little case study conclusion-free for a bit because there are two follow-up pieces. Next, the story of quamina-rs, a Claude-drive port of Quamina to Rust. Finally, Open Source and GenAI?.
Long Links 3 Feb 2026, 8:00 pm
Welcome to the first Long Links of this so-far-pretty-lousy 2026. I can’t imagine that anyone will have time to take in all of these, but there’s a good chance one or two might brighten your day.
Unclassified
Thomas Piketty is always right. For example, Europe, a social-democratic power.
Lying is wrong. Conservatives do it all the time. To be fair, that piece is about the capital-C flavor, as in the Canadian Tories. But still.
Clothing is open-source: “If you slice the different parts off with a seamripper, lay them all down, trace them on new fabric, cut them out, and stitch them back together, you can effectively clone and fork garments.” From Devine Lu Linvega.
The Universe is weird. The Webb telescope keeps showing astronomers things that shouldn’t be there. For example, An X-ray-emitting protocluster at z ≈ 5.7 reveals rapid structure growth; ignore the title and read the Abstract and Main sections. With pretty pictures!
Music
One time in Vegas, I was giving a speech, something about cloud computing, and was surprised to find the venue an ornate velvet-lined theater. I found out from the staff, and then relayed to the audience, that the last human before me to stand on this stage in front of an audience had been Willie Nelson. I was tempted to fall to my knees and kiss the boards. How Willie Nelson Sees America, from The New Yorker, is subtitled “On the road with the musician, his band, and his family” but it ends up being the kernel of a good biography of an interesting person. Bonus link; on YouTube, Willie Nelson - Teatro, featuring Daniel Lanois & Emmylou Harris, Directed by Wim Wenders. Strong stuff.
Speaking of recorded music, check out Why listening parties are everywhere right now. Huh? They are? As a deranged audiophile, sounds like my kind of thing. I’d go.
Somewhere to put worker bees
When I was working at AWS in downtown Vancouver back starting in 2015, a lot of our junior engineers lived in these teeny-tiny little one-room-tbh apartments. It worked out pretty well for them, they were affordable and an easy walk from the office and these people hadn’t built up enough of a life to need much more room. For a while this trend of so-called-“studio” flats was the new hotness in Vancouver and I guess around quite a bit of the developed world. Us older types with families would look at the condo market and tell each other “this is stupid”.
We were right. The bottom is falling out and they’re sitting empty in their thousands. And not just the teeniest either, the whole condo business is in the toilet. It didn’t help that for a few years all the prices went up every year (until they didn’t) and you could make serious money flipping unbuilt condos, so lots of people did (until they didn’t).
Anyhow, here’s a nice write-up on the subject: ‘Somewhere to put worker bees’: Why Canada's micro-condos are losing their appeal. (From the BBC, huh?)
AI AI AI
Sorry, I can’t not relay pro- and anti-GenAI posts, because that conversation is affecting all our lives just now. I am actually getting ready to decloak my own conclusions, but for the moment I’m just sharing essays on the subject that strike me as well-written and enjoyable for their own sake. Thus ‘AI' is a dick move, redux from Baldur Bjarnason. Boy, is he mad.
Sam Ruby has been doing some extremely weird shit, running Rails in the browser, as in without even a network connection or a Ruby runtime. Yes, AI was involved in the construction.
Software
There’s this programming language called Ivy that is in the APL lineage; that acronym will leave young’uns blank but a few greying eyebrows will have been raised. Anyhow, Implementing the transcendental functions in Ivy is delightfully geeky, diving deep with no awkwardness. By no less than Rob Pike.
Check out Mike Swanson’s Backseat Software. That’s “backseat” as in “backseat driver”, which today’s commercial software has now, annoyingly, become. This piece doesn’t make any points that I haven’t heard (or made myself) elsewhere, but it pulls a lot of the important ones together in a well-written and compelling package. Recommended.
Old Googler Harry Glaser reacts with horror to the introduction of advertising by OpenAI, and makes gloomy predictions about how it will evolve. His predictions are obviously correct.
The title says it: Discovering a Digital Photo Editing Workflow Beyond Adobe. It’d be a tough transition for me, but the relationship with Adobe gets harder and harder to justify.
Indigenous reconciliation
Khelsilem is one of the loudest and clearest voices coming out of the Squamish nation, one of the larger and better-organized Indigenous communities around here.
There has been a steady drumbeat of Indigenous litigation going on for decades as a consequence of the fact that the British colonialists who seized the territory in what we now call British Columbia didn’t bother to sign treaties with the people who were already there, they just assumed ownership. The Indigenous people have been winning a lot of court cases, which makes people nervous.
Anyhow, Khelsilem’s The Real Source of Canada's Reconciliation Panic covers the ground. I’m pretty sure British Columbians should read this, and suspect that anyone in a jurisdiction undergoing similar processes should too.
Resonant computing, Black and Blue sky
There’s this thing called the Resonant Computing Manifesto, whose authors and signatories include names you’d probably recognize. Not mine; the first of its Five Principles begins with “In the era of AI…” Also, it is entirely oblivious to the force driving the enshittification of social-media platforms: Monopoly ownership and the pathologies of late-stage capitalism.
Having said that, the vision it paints is attractive. And having said that, it’s now featured on the flags waved by the proponents of ATProto, which is to say Bluesky. See Mike Masnick’s ATproto: The Enshittification Killswitch That Enables Resonant Computing (Mike is on Bluesky Corp’s Board). That piece is OK but, in the comments, Masnick quickly gets snotty about the Fediverse and Mastodon, in a way that I find really off-putting. And once again, says nothing about the underlying economic realities that poison today’s platforms.
I want to like Bluesky, but I’m just too paranoid and cynical about money. It is entirely unclear who is funding the people and infrastructure behind Bluesky, which matters, because if Bluesky Corp goes belly-up, so does the allegedly-decentralized service.
On the other hand, Blacksky is interesting. They are trying to prove that ATProto really can be made decentralized in fact not just in theory. Their ideas and their people are stimulating, and their finances are transparent. I’ll be moving my ATProto presence to Blacksky when I get some cycles and the process has become a little more automated.
Good crypto
The cryptography community is working hard on the problem of what happens should quantum computers ever become real products as opposed to over-invested fever dreams. Because if they ever work, they can probably crack the algorithms that we’ve been using to provide basic Web privacy.
The problem is technically hard — there are good solutions though — and also politically fraught, because maybe the designers or standards orgs are corrupt or incompetent. It’s reasonable to worry about this stuff and people do. They probably don’t need to: Sophie Schmieg dives deep in ML-KEM Mythbusting.
Books
Here’s one of the most heartwarming things I’ve read in months: A Community-Curated Nancy Drew Collection. Reminder: The Internet can still be great.
John Lanchester’s For Every Winner a Loser, ostensibly a review of two books about famous financiers, is in fact an extended howl of (extremely instructive) rage against the financialization of everything and the unrelenting increase in inequality. What we need to do is to take the ill-gotten gains away from these people and put it to a use — any use — that improves human lives.
I talk a lot about late-stage capitalism. But Sven Beckert published a 1,300-page monster entitled Capitalism; the link is to a NYT review and makes me want to read it..
Charlie Stross, the sci-fi author, likes webtoons and recommends a bunch. Be careful, do not follow those links if you’re already short of time. Semi- or fully-retired? Go ahead!
I have history with dictionaries. For several years of my life in the late Eighties, I was the research project manager for the New Oxford English Dictionary project at the University of Waterloo. Dictionaries are a fascinating topic and, for much of the history of the publishing industry, were big money-makers; they dominate any short list of the biggest-selling books in history. Then came the Internet.
Anyhow, Louis Menand’s Is the Dictionary Done For? starts with a review of a book by Stefan Fatsis entitled Unabridged: The Thrill of (and Threat to) the Modern Dictionary which I haven’t read and probably won’t, but oh boy, Menand’s piece is big and rich and polished and just a fantastic read. If, that is, you care about words and languages. I understand there are those who don’t, which is weird. I’ll close with a quote from Menand:
“The dictionary projects permanence,” Fatsis concludes, “but the language is Jell-O, slippery and mutable and forever collapsing on itself.” He’s right, of course. Language is our fishbowl. We created it and now we’re forever trapped inside it.
Quamina v2.0.0 20 Jan 2026, 8:00 pm
There’ve been a few bugfixes and optimizations since 1.5, but the headline is: Quamina now knows regular expressions. This is roughly the fourth anniversary of the first check-in and the third of v1.0.0. (But I’ve been distracted by family health issues and other tech enthusiasms.) Open-source software, it’s a damn fine hobby.
Did I mention optimizations? There are (sob) also regressions; introducing REs had measurable negative impacts on other parts of the system. But it’s a good trade-off. When you ship software that’s designed for pattern-matching, it should really do REs. The RE story, about a year long, can be read starting here.
Quamina facts
About 18K lines of code (excluding generated code), 12K of which are unit tests. The RE feature makes the tests run slower, which is annoying.
Adding Quamina to your app will bulk your executable size up by about 100K, largely due to Unicode tables.
There are a few shreds of AI-assisted code, none of much importance.
A Quamina instance can match incoming data records on my 2023 M2 Mac at millions per second without much dependence on how many patterns are being matched at once. This assumes not too many horrible regular expressions. That’s per-thread of course, and Quamina does multithreading nicely.
Next?
The open issues are modest in number but some of them will be hard.
I think I’m going to ignore that list for a while (PRs welcome, of course) and work on optimization. The introduction of epsilon transitions was required for regular expressions, but they really bog the matching process down. At Quamina’s core is the finite-automaton merge logic, which contains fairly elegant code but generally throws up its hands when confronted with epsilons and does the simplest thing that could possibly work. Sometimes at an annoyingly slow pace.
Having said that, to optimize you need a good benchmark that pressures the software-under-test. Which is tricky, because Quamina is so fast that it’s hard to to feed it enough data to stress it without the feed-the-data code dominating the runtime and memory use. If anybody has a bright idea for how to pull together a good benchmark I’d love to hear it. I’m looking at b.Loop() in Go 1.24, any reason not to go there?
Book?
It occurs to me that as I’ve wrestled with the hard parts of Quamina, I’ve done the obvious thing and trawled the Web for narratives and advice. And, more or less, been disappointed. Yes, there are many lectures and blogs and so on about this or that aspect of finite automata, but they tend to be mathemagical and theoretical and say little about how, practically speaking, you’d write code to do what they’re talking about.
The Quamina-diary ongoing posts now contain several tens of thousands of words. Also I’ve previously written quite a bit about Lark, the world’s first XML parser, which I wrote and was automaton-based. So I think there’s a case for a slim volume entitled something like Finite-state Automata in the Code Trenches. It’d be a big money-maker, I betcha. I mean, when Apple TV brings it to the screen.
Why?
Let’s be honest. While the repo has quite a few stars, I truly have no idea who’s using Quamina in production. So I can’t honestly claim that this work is making the world better along any measurable dimension.
I don’t much care because I just can’t help it. I love executable abstractions for their own sake.
Losing 1½ Million Lines of Go 14 Jan 2026, 8:00 pm
Confession: My title is clickbait-y, this is really about building on the Unicode Character Database to support character-property regexp features in Quamina. Just halfway there, I’d already got to 775K lines of generated code so I abandoned that particular approach. Thus, this is about (among other things) avoiding those 1½M lines. And really only of interest to people whose pedantry includes some combination of Unicode, Go programming, and automaton wrangling. Oh, and GenAI, which (*gasp*) I think I should maybe have used.
Character property matching
I’m talking about regexp incantations like [\p{L}\p{Zs}\p{Nd}], which matches anything that Unicode classifies
as a letter, a space, or a decimal number. (Of course, in Quamina “\” is “~”
for excellent reasons, so that reads
[~p{L}~p{Zs}~p{Nd}].)
(I’m writing about this now because I just launched a PR to enable this feature. Just one more to go before I can release a new version of Quamina with full regexp support, yay.)
Finding the properties
To build an automaton that matches something like that, you have to find out what the character properties are. This information comes from the Unicode Character Database, helpfully provided online by the Unicode consortium. Of course, most programming languages have libraries that will help you out, and that includes Go, but I didn’t use it.
Unfortunately, Go’s library doesn’t get updated every time Unicode does. As of now, January 2026, it’s still stuck at Unicode 15.0.0, which dates to September 2023; the latest version is 17.0.0, last September. Which means there are plenty of Unicode characters Go doesn’t know about, and I didn’t want Quamina to settle for that.
So, I fetched and parsed the famous master file from
www.unicode.org/Public/UCD/latest/ucd/UnicodeData.txt.
Not exactly rocket science, it’s a flat file with ;-delimited fields, of which I only cared about the first
and third. There are some funky bits, such as the pair of nonstandard lines indicating that the Han characters occur
between U+4E00 and U+9FFF inclusive; but still not really taxing.
The output is, for each Unicode category, and also for each category’s complement (~P{L} matches everything
that’s not a letter; note the capital P), a list of pairs of code points, each pair indicating a subset
of the code space where that category applies. For example, here’s the first line of character pairs with category C.
{0x0020, 0x007e}, {0x00a0, 0x00ac}, {0x00ae, 0x0377},How many pairs of characters, you might wonder? There are 37 categories and it’s all over the place but adds up to a lot. The top three categories are L with 1,945 pairs, Ll at 664, and M at 563. At the other end are Zl and Zp, both with just 1. The total number of pairs is 14,811, and the generated Go code is a mere 5,122 lines.
Character-property automata
Turning these creations into finite automata was straightforward: I already had the code to handle regexps like
[a-zA-Z0-9], logically speaking the same problem. But, um, it wasn’t fast. My favorite unit test, an exercise in
sample-driven development with 992 regexps,
suddenly started taking multiple seconds, and my whole unit-test suite expanded from around ten seconds to over twelve; since I
tend to run the unit tests every time I take a sip of coffee or scratch my head or whatever, this was painful. And it occurred to
me that it would be painful in practice to people who want for some good reason or another to load up a bunch of
Unicode-property patterns into a Quamina instance.
So, I said to myself, I’ll just precompute all the automata and serialize them into code. And now we get to the title of this essay; my data structure is a bit messy and ad-hoc and just for the categories, before I got to the complement versions, I was generating 775K lines of code.
Which worked! But, it was 12M in size and while Go’s runtime is fast, there was a painful pause while it absorbed those data structures on startup. Also, opening the generated file regularly caused my IDE (Goland) to crash. And I was only halfway there. The whole approach was painful to work with so I went looking for Plan B.
The code that generates the automaton from the code point pairs is pretty well the simplest thing that could possibly work and it was easy to understand but burned memory like crazy. So I worked for a bit on making it faster and cheaper, but so far have found no low-hanging fruit.
I haven’t given up on that yet. But in the meantime, I remembered Computer Science’s general solution for all performance problems, by which I mean caching. So now, any Quamina instance will compute the automaton for a Unicode property the first time it’s used, then remember it. So now Quamina’s speed at adding Unicode-property regexps to an instance has increased from 135/second to 4,330, a factor of thirty and Good Enough For Rock-n-Roll.
It’s worth pointing out that while building these automata is a heavyweight process, Quamina can use them to match input messages at its typical rates, hundreds of thousands to millions per second. Sure, these automata are “wide”, with lots of branches, but they’re also shallow, since they run on UTF-8 encoded characters whose maximum length is four and average length is much less. Most times you only have to take one or two of those many branches to match or fail.
Should I have used Claude?
This particular segment of the Quamina project included some extremely routine programming tasks, for example fetching and parsing UnicodeData.txt, computing the sets of pairs, generating Go code to serialize the automata, reorganizing source files that had become bloated and misshapen, and writing unit tests to confirm the results were correct.
Based on my own very limited experience with GenAI code, and in particular after reading Marc Brooker’s On the success of ‘natural language programming’ and Salvatore (“antirez”) Sanfilippo’s Don't fall into the anti-AI hype, I guess I’ve joined the camp that thinks this stuff is going to have a place in most developers’ toolboxes.
I think Claude could have done all that boring stuff, including acceptable unit tests, way faster than I did. And furthermore got it right the first time, which I didn’t.
So why didn’t I use Claude? Because I don’t have the tooling set up and I was impatient and didn’t want to invest the time in getting all that stuff going and improving my prompting skills. Which reminds me of all the times I’ve been trying to evangelize other developers on a better way to do things and was greeted by something along the lines of “Fine, but I’m too busy right now, I’ll just going on doing things the way I already know how to.”
Does this mean I’m joining the “GenAI is the future and our investments will pay off!” mob? Not in the slightest. I still think it’s overpriced, overhyped, and mostly ill-suited to the business applications that “thought leaders” claim for it. That word “mostly” excludes the domain of code; as I said here, “It’s pretty obvious that LLMs are better at predicting code sequences than human language.”
And, as it turns out, the domain of Developer Tools has never been a Big Business by the standards of GenAI’s promoters. Nor will it ever be; there just aren’t enough of us. Also, I suspect it’ll be reasonably easy in the near future for open-source models and agents to duplicate the capabilities of Claude and its ilk.
Speaking personally, I can’t wait for the bubble to pop.
Quamina.next?
After I ship the numeric-quantifier feature, e.g. a{2-5}, Quamina’s regexp support will be complete and if no
horrid bugs pop up I’ll pretty quickly release Quamina 2.0. Regexps in pattern-matching software are a qualitative difference-maker.
After that I dunno, there are lots more interesting features to add.
Unfortunately, a couple years into my Quamina work, I got distracted by life and by other projects, and ignored it. One result is that so did the other people who’d made major contributions and provided PR reviews. I miss them and it’s less fun now. We’ll see.
Regexp Lessons 1 Jan 2026, 8:00 pm
I’m just landing a
chonky PR in
Quamina whose effect is to enable the + and * regexp
features. As in my
last chapter, this is a disorderly war story not an essay, and
probably not of general interest. But
as I said then, the people who care about coercing finite automata into doing useful things at scale are My People (there are
dozens of us).
2014-2026
As I write this, I’m sitting in the same couch in my Mom’s living room in Saskatchewan where, on my first Christmas after joining AWS, I got the first-ever iteration of this software to work. That embryo’s mature form is available to the world as aws/event-ruler. (Thanks, AWS!) Quamina is its direct descendent, which means this story is entering its twelfth year.
Mom is now 95 and good company despite her failing memory. I’ve also arrived at a qualitatively later stage of life than in 2014, but would like to report back from this poorly-lit and often painful landscape: Executable abstractions are still fun, even when you’re old.
Anyhow, the reason I’m writing all this stuff isn’t to expound on the nature of finite automata or regular expressions, it’s to pass on lessons from implementing them.
Lesson: Seek out samples
In a previous episode I used the phrase Sample-driven development to describe my luck in digging up 992 regexp test cases, which reduced task task from intimidating to approachable. I’ve never previously had the luxury of wading into a big software task armed with loads of test cases written by other people, and I can’t recommend it enough. Obviously you’re not always going to dig this sort of stuff up, but give it a sincere effort.
Lesson: Break up deliverables
I decomposed regular expressions into ten unique features, created an enumerated type to identify them, and implemented them by ones and twos. Several of the feature releases used techniques that turned out to be inefficient or just wrong when it came to subsequent features. But they worked, they were useful, and my errors nearly all taught me useful lessons.
Having said that, here’s some cool output that combines this lesson and the one above, from the unit test that runs those test cases. Each case has a regexp then one or more samples each of strings that should and shouldn’t match. I instrumented the test to report the usage of regexp features in the match and non-match cases.
Feature match test counts: 32 '*' zero-or-more matcher 27 () parenthetized group 48 []-enclosed character-class matcher 7 '.' single-character matcher 29 |-separated logical alternatives 16 '?' optional matcher 29 '+' one-or-more matcher Feature non-match test counts: 45 '+' one-or-more matcher 24 '*' zero-or-more matcher 31 () parenthetized group 49 []-enclosed character-class matcher 6 '.' single-character matcher 32 |-separated logical alternatives 21 '?' optional matcher
Of course, since most of the tests combine multiple features, the numbers for all the features get bigger each time I implement a new one. Very confidence-building.
Lesson: Thompson’s construction
This is the classic nineteen-sixties regular-expression implementation by Ken Thompson, described in Wikipedia here and (for me at least) more usefully, in a storytelling style by Russ Cox, here.
On several occasions I rushed ahead and implemented a feature without checking those sources, because how hard could it be? In nearly every case, I had problems with that first cut and then after I went and consulted the oracle, I could see where I’d gone wrong and how to fix it.
So big thanks, Ken and Russ.
Lesson: List crushing
In some particularly nasty regular expressions that
combine [] and ? and + and *, you can
get multiple states connected in complicated ways with epsilon links.
In Thompson’s Construction, traversing an NFA transitions not just from one state to another but from a current set of states
to a next set, repeat until you match or fail. You also compute epsilon closures as you go along; I’m skipping over details
here. The problem was that traversing these pathologically complex regexps with a sufficiently long string was leading to an
exponential explosion in the current-states and next-states sizes — not a figure of speech, I mean
O(2N). And despite the usage of the word “set” above, these weren’t, they contained endless
duplicates.
The best solution would be to study the traversal algorithm and improve it so it didn’t emit fountains of dupes. That would be hard. The next-best would to turn these things into actual de-duped sets, but that would require a hash table right in the middle of the traversal hot spot, and be expensive.
So what I did was to detect whenever the next-steps list got to be longer than N, sorted it, and crushed out all the dupes. As I write, N is now 500 based on running benchmarks and finding a value that makes number go down.
The reason this is good engineering is that the condition where you have to crush the list almost never happens, so in the
vast majority of cases the the only cost is an if len(nextSteps)>N comparison. Some may find this approach
impure, and they have a point. I would at some point like to go back and find a better upstream approach. But for now it’s still
really fast in practice, so I sleep soundly.
Lesson: Hell’s benchmark
I’ve written before about my struggles with the benchmark where I merge 12,959 wildcard patterns together. Back before I was doing epsilon processing correctly, I had a kludgey implementation that could match patterns in the merged FA at typical Quamina speeds, hundreds of thousands per second. With correct epsilon general-purpose epsilon handling, I have so far not been smart enough to find a way to preserve that performance. With the full 13K patterns, Quamina matches at less than 2K/second, and with a mere thousand, at 16K/second. I spent literally days trying to get better results, but decided that it was more valuable to Quamina to handle a large subset of regular expressions correctly than to run idiotically large merges at full speed.
I’m pretty sure that given enough time and consideration, I’ll be able to make it better. Or maybe someone else who’s smarter than me can manage it.
Question: What next?
The still-unimplemented regexp features are:
{lo,hi} : occurrence-count matcher
~p{} : Unicode property matcher
~P{} : Unicode property-complement matcher
[^] : complementary character-class matcher
Now I’m wondering what to do next. [^] is pretty easy I think and is useful, also I get to invert a
state-transition table. The
{lo,hi} idiom shouldn’t be hard but I’ve been using regexps for longer than most of you have been alive and have
never felt the need for it, thus I don’t feel much urgency. The Unicode properties I think have a good fun factor just because
processing the Unicode character database tables is cool. And, I’ve used them.
[Update: the [^] thing took a grand total of a couple of hours to build and test. Hmm, what next?]
Lesson: Coding while aging
I tell people I keep working on code for the sake of preserving my mental fitness. But mostly I do it for fun. Same for writing about it. So, thanks for reading.
Humanist Plumbing 18 Dec 2025, 8:00 pm
What happened was, a faucet started dripping. And then I managed to route around the malignant machineries of late-stage capitalism. These days, that’s almost always a story worth telling.
Normally, faced with a drip, we’d pull out the old cartridge, take it to the hardware store, and buy another to swap in. But the fixture in our recently-acquired place was kind of exotic and abstract and neither of us could figure it out. We were gloomy because we’ve had terrible luck over the years with the local plumbing storefronts. So…
The neighbors
Our neighborhood has an online chat; both sides of the streets in a square around a single city block. This is our first experience with such a thing. I gather that these don’t always work out well, but this one has been mostly pretty great.
So at 9AM I posted “Hey folks, looking for a plumber recommendation” and by ten there were three.
[Late-stage capital: “You’re supposed to ask the AI in your browser. It’ll provide a handy link to a vendor based on geography and reviews but mostly advertising spend. Why would you want to talk to other people?”]
Thomas
I picked a neighbor’s suggestion, first name Thomas, and called the number. “Thomas here” on the second ring. I explained and he said “What’s the brand name? If it’s one of those Chinese no-names I probably have to replace the whole thing.” I said “No idea, but I’ll take a picture and send it to you.”
Turns out the brand was Riobel, never heard of them. I texted Thomas a picture and he got right back to me: “That’s high-end, it’s got a lifetime warranty. I’ll come by a little after 5 and take it out. Their dealer is in PoCo (an outer suburb) and I live out there, so I can swap it.”
[Late-stage capital: “You’re supposed to engage with the chatbot on the site we sent you to, which will integrate with your calendar and arrange for a diagnostic visit a week from Wednesday. You could call them but you’d be in voice-menu hell and eventually end up at the same chatbot.”]
When Thomas showed up, with a sidekick, he was affable and obviously competent. Within five minutes I was glad I’d called for help; that faucet’s construction was highly non-obvious. Thomas knew what he was doing and it still took him the best part of a half-hour to get it all disassembled and the cartridge extracted.
Nothing’s perfect
The next morning, a text from Thomas: “Bad news. That part is back-ordered till May at Riobel’s dealer. We can maybe get it online but you’d have to pay.” He attached a screenie of a Web search for the part number; there were several online vendors.
It’s irritating that the “lifetime warranty” doesn’t seem to be helping me, but to be fair, the part was initially installed in 2011.
[Late-stage capital: “Lifetime warranty? Huh? Oh, of course you mean our VIP-class subscription offering, that’s monthly with a discount for annual up-front payment.” (And the part would still be back-ordered.)]
Kolani
High-end plumbing parts are expensive. But one of Thomas’ recommendations, Kolani Kitchen and bath, was asking less.
They had a phone number on their Web site so I called it and the voice menu only had three options: Location, opening hours, and Operator. The operator was an intelligent human and picked up right away. “Hi, I’m looking at ordering a cartridge and wanted to see if you had it in stock.” “Gimme the part number?” I did and she went away for a couple of minutes and came back “Yeah, it’s in stock.” So I ordered it and I have a tracking number.
[Late-stage capital: “There aren’t supposed to be independent dealers; the manufacturer has taken PE money and eliminated the middlemen to better capture all the value-add. Or maybe there’ll be a wholesaler, but just one, because another PE rolled up all the distributors to maximize pricing power. Either way, you won’t be able to get a human on the line.”]
Payment
Next morning, I got an email that my order had been canceled. So I called that intelligent operator and she said “I was going to email you. Our system won’t take payment if the billing and delivery addresses are different. Sorry. If you’re in a hurry you could do an e-transfer?” (In Canada, all the banks are in a payments federation that makes this dead easy.) So I did and the part has shipped.
[Late-stage capital: “What? If you’d used our Integrated online payment offering, it would all just work. What if it doesn’t, you ask? Yeah, sucks to be you in that situation, of course there’d be nobody you could talk to about that.”]
Thomas came by again to put the old cartridge back in for now and said “This thing, don’t worry about a drip, it’s not fast and it probably won’t get worse. Text me when the new part gets in.”
Late-stage capitalism
It won’t be missed when it’s gone.
After the Bubble 7 Dec 2025, 8:00 pm
The GenAI bubble is going to pop. Everyone knows that. To me, the urgent and interesting questions are how widespread the damage will be and what the hangover will feel like. On that basis, I was going to post a link on Mastodon to Paul Krugman’s Talking With Paul Kedrosky. It’s great, but while I was reading it I thought “This is going to be Greek to people who haven’t been watching the bubble details.” So consider this a preface to the Krugman-Kedrosky piece. If you already know about the GPU-fragility and SPV-voodoo issues, just skip this and go read that.
Depreciation
When companies buy expensive stuff, for accounting purposes they pretend they haven’t spent the money; instead they “depreciate” it over a few years. That is to say, if you spent a million bucks on a piece of gear and decided to depreciate it over four years, your annual financials would show four annual charges of $250K. Management gets to pick your depreciation period, which provides a major opening for creative accounting when the boss wants to make things look better or worse than they are.
Even when you’re perfectly honest it can be hard to choose a fair figure. I can remember one of the big cloud vendors announcing they were going to change their fleet depreciation from three to four years and that having an impact on their share price.
Depreciation is orderly whether or not it matches reality: anyone who runs a data center can tell you about racks with 20 systems in them that have been running fine since 2012. Still, orderly is good.
In the world of LLMs, depreciation is different. When you’re doing huge model-building tasks, you’re running those expensive GPUs flat out and red hot for days on end. Apparently they don’t like that, and flame out way more often than conventional computer equipment. Nobody who is doing this is willing to come clean with hard numbers but there are data points, for example from Meta and (very unofficially) Google.
So GPUs are apparently fragile. And they are expensive to run because they require huge amounts of electricity. More, in fact, than we currently have, which is why electrical bills are spiking here and there around the world.
Why does this matter? Because when the 19th-century railway bubble burst, we were left with railways. When the early-electrification bubble burst, we were left with the grid. And when the dot-com bubble burst, we were left with a lot of valuable infrastructure whose cost was sunk, in particular dark fibre. The AI bubble? Not so much; What with GPU burnout and power charges, the infrastructure is going to be expensive to keep running, not something that new classes of application can pick up and use on the cheap.
Which suggests that the post-bubble hangover will have few bright spots.
SPVs
This is a set of purely financial issues but I think they’re at the center of the story.
It’s like this. The Big-Tech giants are insanely profitable but they don’t have enough money lying around to build the hundreds of billions of dollars worth of data centers the AI prophets say we’re going to need. Which shouldn’t be a problem; investors would line up to lend them as much as they want, because they’re pretty sure they’re going to get it back, plus interest.
But apparently they don’t want to borrow the money and have the debts on their balance sheet. So they’re setting up “Special Purpose Vehicles”, synthetic companies that are going to build and own the data centers; the Big Techs promise to pay to use them, whether or not genAI pans out and whether or not the data centers become operational. Somehow, this doesn’t count as “debt”.
The financial voodoo runs deep here. I recommend Matt Levine’s Coffee pod financing and the Financial Times’ A closer look at the record-smashing ‘Hyperion’ corporate bond sale. Levine’s explanation has less jargon and is hilarious; the FT is more technical but still likely to provoke horrified eye-rolls.
If you think there’s a distinct odor of 2008 around all this, you’d be right.
If the genAI fanpholks are right, all the debt-only-don’t-call-it-that will be covered by profits and everyone can sleep sound. Only it won’t. Thus, either the debts will apply a meat-axe to Big Tech profits, or (like 2008) somehow they won’t be paid back. If whoever’s going to bite the dust is “too big to fail”, the money has to come from… somewhere? Taxpayers? Pension funds? Insurance companies?
Paul K and Paul K
I think I’ve set that piece up enough now. It points out a few other issues that I think people should care about. I have one criticism: They argue that genAI won’t produce sufficient revenue from consumers to pay back the current investment frenzy. I mean, they’re right, it won’t, but that’s not what the investors are buying. They’re buying the promise, not of more revenue, but of higher profits that happen when tens of millions of knowledge workers are replaced by (presumably-cheaper) genAI.
I wonder who, after the loss of those tens of millions of high-paid jobs, are going to be the consumers who’ll buy the goods that’ll drive the profits that’ll pay back the investors. But that problem is kind of intrinsic to Late-stage Capitalism.
Anyhow, there will be a crash and a hangover. I think the people telling us that genAI is the future and we must pay it fealty richly deserve their impending financial wipe-out. But still, I hope the hangover is less terrible than I think it will be.
Tracy Numbers 2 Dec 2025, 8:00 pm
Here’s a story about African rhythms and cancer and combinatorics. It starts a few years ago when I was taking a class in Afro-Cuban rhythms from Russell Shumsky, with whom I’ve studied West-African drumming for many years. Among the basics of Afro-Cuban are the Bell Patterns, which come straight out of Africa. The most basic is the “Standard Pattern”, commonly accompanying 12/8music. “12/8” means there are four clusters of three notes and you can count it “one-two-three two-two-three three-two-three four-two-three”. It feels like it’s in four, particularly when played fast.
Here’s the standard bell pattern in music notation. Instead of one 12/8 bar, I’ve broken it into four 3/8 chunks. Let’s call those “mini-measures”; I’ll use that or just “minis” in the rest of this piece.
Bell patterns are never played in isolation, but circularly on fast repeat, so the first note immediately follows the last.
In the sound sample, I’m playing a background beat on a conga, emphasizing the beginning of the 12/8 measures. The actual bell pattern is on the high “child” bell of a Gankoqui, an African dual-cowbell set.

“þ” the cat was trying bell patterns but
unfortunately
cats can’t count as high as 12. Collar by
BirdsBeSafe.com.
That’s my Gankoqui. I bought it off someone on Etsy who imports them from Ghana. It came with that little thin stick that sounds nice, but sometimes I use a regular drumstick when things get loud.
The problem
Russell’s a good teacher and the standard pattern isn’t that tricky, but I just couldn’t get a grip on it. It’s a little harder than it looks what with cycling it really fast, and then you’re playing it against complicated music with other instrumental voices. I probably would have got there, but the lessons ran out of gas in the depths of Covid.
Introducing Tracy
She was Russell’s long-time partner, a good person and good drummer too. When you were struggling with a complex rhythm it was helpful to watch Tracy’s hands, because she was always on the beat.
Tracy lived with stage four metastatic cancer for many years and braved endless awful rounds of therapy while remaining generally cheerful. She could be morbidly funny; I bought her congas (you can hear one behind the beat in the samples) when she had a storage-space problem. She told me she was carefully planning her finances so she’d run out of money just before the cancer got her.
I always enjoyed any time I spent with her. Then, a dozen years into her cancer journey, this last summer it got into her brain and it was pretty clear her end times were upon her.
The hospice
Tracy’s last months were spent at St. John Hospice in Vancouver’s far west. I can’t say enough good things about it. If you’re near Vancouver and your death becomes imminent, try to be there if you can’t be at home. It’s comfortable and the staff are expert and infinitely kind. The rules that apply at hospices are different from those at hospitals; for example, Tracy’s cat joined her in residency and had the run of the place.
I (and other fans of Russell and Tracy) visited the hospice a few times. My last visit was just days before her death and, while she was fatigued and spaced-out, it was still Tracy. I wasn’t close enough to call her a friend, but I miss her.
We got to talking about Afro-Cuban music and I laughed at myself, saying how I never could get that damn bell pattern down. Said Russell: “Oh, you mean the standard 12/8 pattern? Tracy, let’s show him” and on the second try, they were doing it together, just voices, ta ta ta-ta, ta ta ta.
Driving home from the hospice, I told myself that if Tracy could manage the bell pattern in her condition, I could bloody well learn it. So I studied the details and used a metronome app and after a while I thought I had it down pretty well.
Sounds cool
I go to a weekly by-invitation African drum jam where I’m on the weaker end of the skill spectrum. The first time a 12/8 came along after I thought I’d learned the pattern, I had to summon up courage and then I fluffed the first few bars. But after a while I was grooving along and smiling and thinking the bell sounded pretty cool against the thunder of all the djembés and dununs.
And, even played amateurishly, it does sound cool. Let’s have another look at the music.
West-African drumming often tries to achieve rhythmic tension, where a given note could fit in multiple ways and your ear is not 100% sure what’s going on. The standard pattern does this, twice.
Remember, I said that 12/8 sounds like it’s “in four”, especially if you hit the first beat of each of the four mini-measures. But two of the four minis here go around the first note, weakening the 4/4 feel. Especially on that third mini; you can feel the beat slide by the missing “one”.
Also, the last three notes are evenly spaced two beats apart, so six of them would fill the 12-beat pattern, suggesting that this might be in triple time, not 12/8.
The effect, to my ears, is of the bell, higher-pitched than the drums, shifting against the rhythm, or even dancing across it. At the drum jam, at almost any given moment it won’t be just drums, one or more people will have clave sticks or rattles or tambourines or cowbells weaving through the beat.
Mixing it up
After I felt confident playing the standard pattern, it still sounded cool, but I wanted to branch out, not just go around and around the same seven notes. So the first thing I did was start mixing in a few of these.
This repeats the second bar through the end of the phrase. In the sound sample I mix it up with the standard pattern. It’s got less rhythmic tension but on the other hand flows along smoothly with the drum thunder. Also you don’t have to think at all, so you can enjoy listening to what the other people are playing.
Then I got a little more ambitious and reshuffled:
The mini-measures are the same as in the standard pattern, just in a different order. Anyhow, this kind of thing is fun.
Combinatorics
Then one evening I was lying in bed, thoughts wandering, and wondered “How many bell patterns are there?” A little mental math showed that of course there are eight possible arrangements of tones in a 3-note mini-measure. Here they are:

I’ll use the boxed numbers to identify the minis.
Why are the minis numbered in that order? Every computer programmer looking at this already knows, but for the rest of you: If the notes are ones and the rests are zeroes, they are the eight binary numbers between zero and seven inclusive. So each number’s binary bits show where the drumstrokes are. By the way, numbers four through seven have a note on the one beat, zero through three don’t.
Is it weird to have a zero i.e. silent mini? I don’t think so, sometimes spaces between the notes really matter.
Patterns
Anyhow, the original question was about the number of different bell patterns. Each has four mini-measures with 8 possible values. So the answer is 8 ⨉ 8 ⨉ 8 ⨉ 8, which is 4,096.
And each of them can be identified by four little numbers, ranging from T0000 (I can hear the bandleader yelling “gimme zeroes for the sax break”) to T7777, a flurry of eighth notes that you might use in the big encore-number finish designed to leave the audience yelling as you walk off stage. The standard bell pattern is T5325; in binary “101 011 010 101” and the 1’s are drumstrokes. The first variation above is T5333 and the second is T5253.
The “T” in front of each bell pattern number is for Tracy.
If you go look at the Wikipedia Bell-pattern article, they emphasize that there are lots of different patterns. Now they all have numbers! The article makes special mention of T5124, T5221, and T5244.
But why, Tim?!
I’m a computer programmer with a Math degree, and an amateur musician. Anyone who thinks that these are disjoint disciplines is wrong. And, I think the notation is (on a very small scale) kind of pleasing.
But the work has actually helped me. Now that I’ve considered each mini-measure and its personality. I find all of them sneaking into my Gankoqui excursions, which have gotten noticeably weirder, for example T5635. Nobody’s threatened to kick me out of the jam, so far.
Also, this has given me a real appreciation of whoever it was that, probably thousands of years ago and certainly in Africa, picked the “standard” pattern as, well, standard. Because it’s great.
What’s missing?
You may have noticed that Gankoquis have two bells and I’ve been ignoring that fact. Normally you’d play these patterns on the smaller “child” bell, but sometimes bringing the big parent bell in for a couple of strokes works well. Here’s an example (h/t Russell).
Also, this discussion has been limited to 3/8 minis in 12/8 measures. There’s another whole universe of 4/4 rhythms that also have bell patterns (but everything exists in the shadow of the clave rhythm). In that world a pattern has four measures, each of which can have sixteen possible values, so there are 65,536 different ones.
And I could repeat the numbers construction above for 4/4. But I’m not going to, because the rewards feel smaller. In my experience, 4/4 rhythms lope smoothly along and everyone knows where the one is even when there’s no note on it, so there’s less ambiguity to work with. Anyhow, any neophyte (like for example me) can play a pretty smooth bell line against 4/4; just start with clave and add variations (or don’t) and you’ll be fine.
Useful?
These numbers are just elementary mathemusical fun. If anyone else wanted to use them that’d be a pleasant surprise. If “anyone else” is you, go ahead, but they have a name and you have to use it. These are called Tracy Numbers.
Colophon
Music fragments by MuseScore Studio. Sound samples facilitated by GarageBand, a Shure MV51, and PSB Alphas.
Page processed in 2.423 seconds.
Powered by SimplePie 1.4-dev, Build 20170403172323. Run the SimplePie Compatibility Test. SimplePie is © 2004–2026, Ryan Parman and Geoffrey Sneddon, and licensed under the BSD License.